SERVICE DEFINITION

Ontology {noun}
[uncountable] a branch of philosophy that deals with the nature of existence
[countable] a list of concepts and categories in a subject area
that shows the relationships between them
In simple words, one can say that ontology is the study of what there is.
In simple words, one can say that ontology is the study of what there is.
Ontology as a branch of philosophy is the science of what is, of the
kinds and structures of objects, properties, events, processes, and
relations in every area of reality. “Ontology” is often used by
philosophers as a synonym of “metaphysics”.
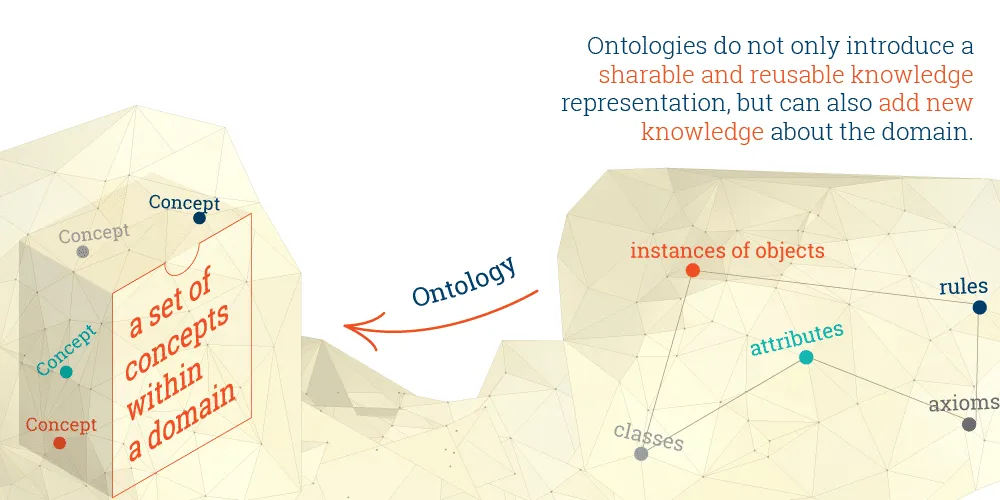
An ontology is a formal description of knowledge as a set of concepts
within a domain and the relationships that hold between them. To
enable such a description, we need to formally specify components such
as individuals (instances of objects), classes, attributes and
relations as well as restrictions, rules and axioms. As a result,
ontologies do not only introduce a sharable and reusable knowledge
representation but can also add new knowledge about the domain. It
ensures a common understanding of information and makes explicit
domain assumptions thus allowing organizations to make better sense of
their data.
In computer science, ontology refers to a formal representation of a
domain of knowledge or a conceptual model that defines a set of
concepts and the relationships between them, often represented in a
hierarchical structure or graph. Ontologies are used in fields such as
artificial intelligence, knowledge management, and the semantic web to
enable the sharing and reuse of knowledge across different
applications and domains.
The ontology data model can be applied to a set of individual facts to
create a knowledge graph – a collection of entities, where the types
and the relationships between them are expressed by nodes and edges
between these nodes, By describing the structure of the knowledge in a
domain, the ontology sets the stage for the knowledge graph to capture
the data in it.
If we bring back the definition of formal ontology from above, and then we think of data and information, it’s possible to set up a framework to study data and its relation to other data. In this framework we represent information in an especially useful way. Information represented in a particular formal ontology can be more easily accessible to automated information processing, and how best to do this is an active area of research in computer science like data science. The use of the formal ontology here is representational. It is a framework to represent information, and as such it can be representationally successful whether or not the formal theory used in fact truly describes a domain of entities.
Ontology seeks to provide a definitive and exhaustive classification
of entities in all spheres of being. The classification should be
definitive in the sense that it can serve as an answer to such
questions as: What classes of entities are needed for a complete
description and explanation of all the goings-on in the universe? Or:
What classes of entities are needed to give an account of what makes
true all truths? It should be exhaustive in the sense that all types
of entities should be included in the classification, including also
the types of relations by which entities are tied together to form
larger wholes.
Methods of Ontology: The methods of ontology – henceforth
in philosophical contexts always used in the adequatist sense – are
the methods of philosophy in general. They include the development of
theories of wider or narrower scope and the testing and refinement of
such theories by measuring them up, either against difficult
counter-examples or against the results of science. These methods were
familiar already to Aristotle himself. In the course of the twentieth
century a range of new formal tools became available to ontologists
for the development and testing of their theories. Ontologists
nowadays have a choice of formal frameworks (deriving from algebra,
category theory, mereology, set theory, topology) in terms of which
their theories can be formulated. These new formal tools, along with
the language of formal logic, can in principle allow philosophers to
express intuitive ideas and definitions in clear and rigorous fashion,
and, through the application of the methods of formal semantics, they
can allow also for the testing of theories for logical consistency and
completeness.
To create effective representations it is an advantage if one knows
something about the things and processes one is trying to represent.
(We might call this the Ontologist’s Credo.) The attempt to satisfy
this credo has led philosophers to be maximally opportunistic in the
sources they have drawn upon in their ontological explorations of
reality and in their ontological theorizing.
Ontology and Information Science: In a related development,
also hardly noticed by philosophers, the term “ontology” has gained
currency in recent years in the field of computer and information
science (Welty & Smith 2001). The big task for the new “ontology”
derives from what we might call the Tower of Babel problem. Different
groups of data- and knowledgebase system designers have their own
idiosyncratic terms and concepts by means of which they build
frameworks for information representation. Different databases may use
identical labels but with different meanings; alternatively the same
meaning may be expressed via different names. As ever more diverse
groups are involved in sharing and translating ever more diverse
varieties of information, the problems standing in the way of putting
this information together within a single system increase
geometrically. Methods must be found to resolve the terminological and
conceptual incompatibilities which then inevitably arise. Initially,
such incompatibilities were resolved on a case-by-case basis.
Gradually, however, it was recognized that the provision, once and for
all, of a common reference ontology – a shared taxonomy of entities –
might provide significant advantages over such case-by-case
resolution, and the term “ontology” came to be used by information
scientists to describe the construction of a canonical description of
this sort. An ontology is in this context a dictionary of terms
formulated in a canonical syntax and with commonly accepted
definitions designed to yield a lexical or taxonomical framework for
knowledge representation which can be shared by different
information-systems communities. More ambitiously, an ontology is a
formal theory within which not only definitions but also a supporting
framework of axioms is included (perhaps the axioms themselves provide
implicit definitions of the terms involved). The methods used in the
construction of ontologies thus conceived are derived on the one hand
from earlier initiatives in database management systems. But they also
include methods similar to those employed in philosophy (as described
in Hayes 1985), including the methods used by logicians when
developing formal semantic theories.
The potential advantages of ontology thus conceived for the purposes
of information management are obvious. Each group of data analysts
would need to perform the task of making its terms and concepts
compatible with those of other such groups only once – by calibrating
its results in the terms of the single canonical backbone language. If
all databases were calibrated in terms of just one common ontology (a
single consistent, stable, and highly expressive set of category
labels), then the prospect would arise of leveraging the thousands of
person-years of effort that have been invested in creating separate
database resources in such a way as to create, in more or less
automatic fashion, a single integrated knowledge base of a scale
hitherto unimagined, thus fulfilling an ancient philosophical dream of
a Great Encyclopedia comprehending all knowledge within a single
system.
Reference:
- What are Ontologies? | Ontotext Fundamentals Series
- Ontology and Data Science. How the study of what there is can help… | by Favio Vázquez | Towards Data Science
- Barry Smith- Luciano Floridi (ed.), Blackwell Guide to the Philosophy of Computing and Information. Oxford: Blackwell
- MIT - Ontology and Social Construction